sentiment-analysis-mental-health
Sentiment analysis for mental conversation data classification
Project Overview
This project uses transformer encoder layer to build a model for mental health data classification study. The goal is to get myself familiar with NLP and transformer models.
Datasets
This project uses datasets from kaggle Sentiment Analysis for Mental Health provided by Suchintika Sarkar. Details can be found on datasets page on kaggle.
The inputs of the dataset are text including conversation and social media posts, etc. The outputs are several classes of “diagnoses”.
Modeling
The model is based on transformer encoder only since this is a classification model, no decoder is needed. Code is based on Pytorch transformer encoder layer. Considering the relatively small data size, the model cannot be too big otherwise it would be easily overfitted.
Training
Initially the character based simple tokenizer was used, however, the model was unable to perform beyond 75% accuracy. The problem is character based tokenizer lost too much information, especially for emoji, which will be break down to meaningless symbols. After switching to Byte-Pair Encoding tokenizer provided by Hugging Face tokenizers package, the model can easily reach 80% validation accuracy and eventually reached 90% accuracy.
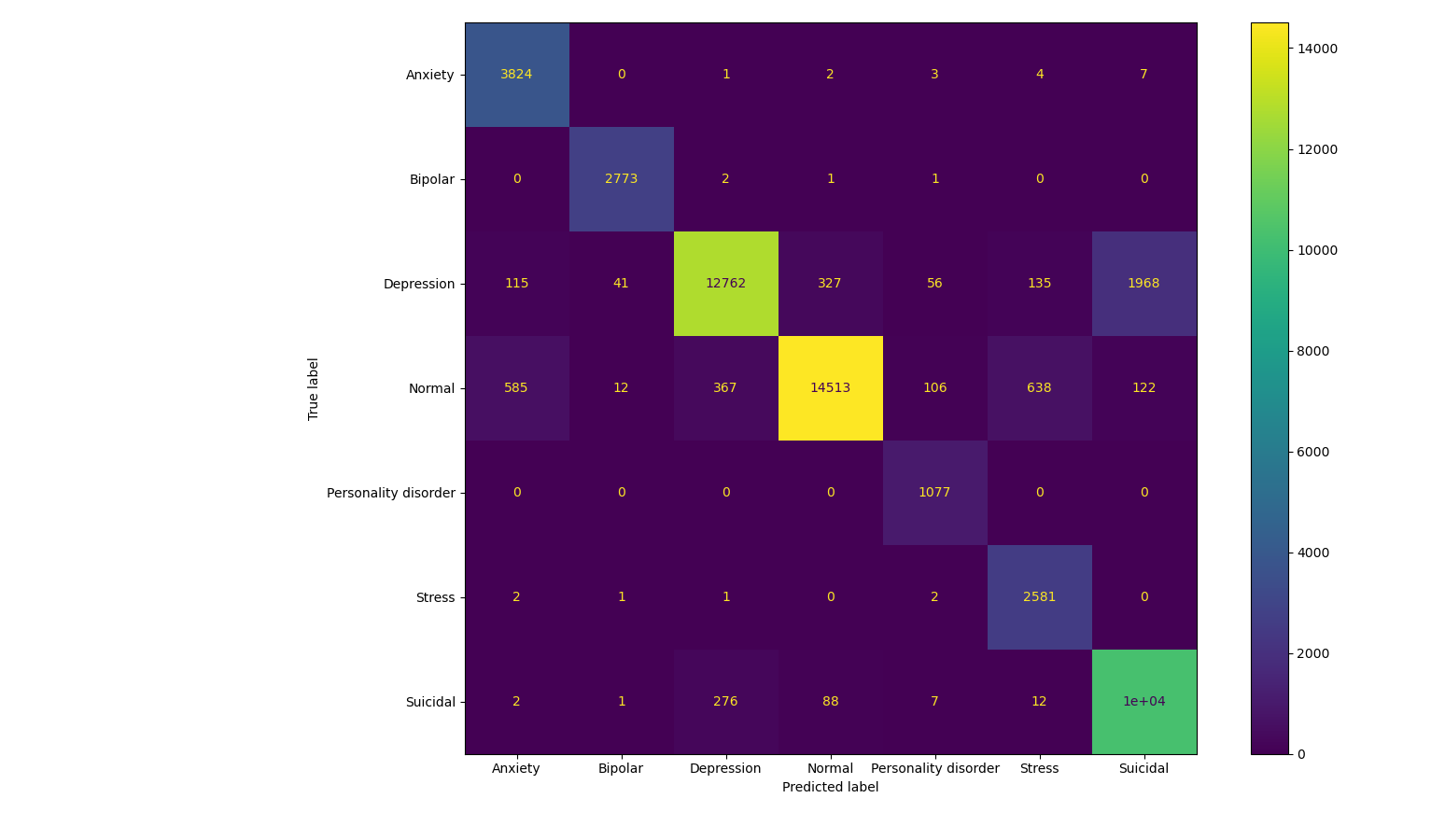
Validation
The model was tested with validation data and customized input.
Notebook
For training process and model details, the code can be found here
For evaluation, a notebook can be found here